Sismología
El aprendizaje automático tiene aplicaciones prácticas en decenas de disciplinas, pudiendo predecir el valor de una variable resultante en base a una serie de atributos y teniendo acceso al historial de comportamiento de dicha variable.
En este caso particular, se propone como objetivo predecir la ocurrencia de un sismo de grado 7 (Richter) o mayor en base al historial de sismos.
Esto, por supuesto, con un cierto margen de error.
La variable temporal es continua. Es decir, bajo este escenario el modelo predictivo dará como resultado un rango temporal con un intervalo de confianza del 95%.
También podría convertirse en un problema de clasificación, para el cual existen diversos algoritmos de machine learning
Obtención de datos
La base de datos a descargar se encuentra alojada en el sitio oficial del programa de riesgos sísmicos de Estados Unidos USGS www.usgs.gov
Este sitio cuenta con una API para consultar sismos en base a parámetros de entrada y su documentación se encuentra disponible en
https://earthquake.usgs.gov/fdsnws/event/1/
Por ejemplo, la siguiente URL devuelve en formato XML los sismos ocurridos a nivel mundial el año 1950, con magnitud igual 0 mayor a 5
a href=»https://earthquake.usgs.gov/fdsnws/event/1/query?format=xml&starttime=1950-01-01&endtime=1950-12-31&minmagnitude=5
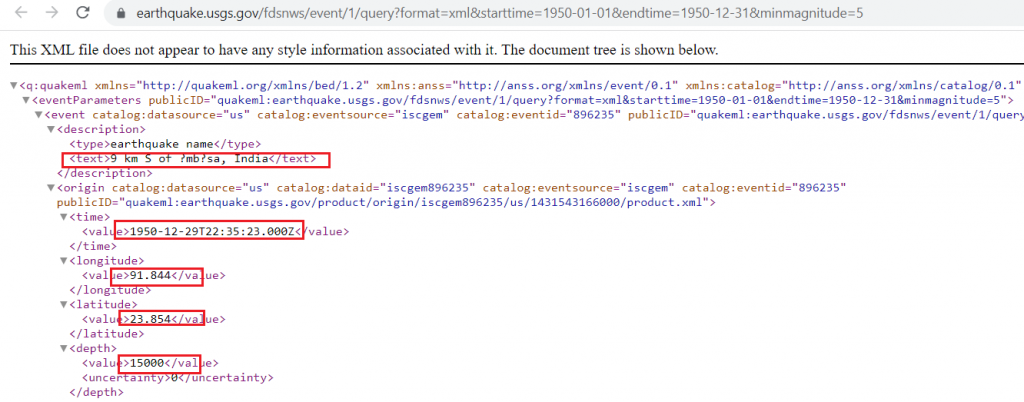
El primer paso es crear en Python una rutina que permita realizar el llamado HTTP señalado anteriormente y almacenar el resultado en formato CSV para ser analizado posteriormente.
El sitio presenta información desde el año 1900 hasta la fecha actual.
Debido a esto, el llamado a esta API debe dividirse de manera de no extraer 120 año de datos de una sola vez.
Existen dos librerías de utilidad para este caso
Selenium: Permite simular un navegador web, extrayendo el código fuente
Beautifulsoup: Permite automatizar la extracción de etiquetas XML
El enfoque a seguir es el siguiente
- Generar la URL para extraer los datos de los sismos iguales o mayores a magnitud 5, comenzando con el año 1900.
Esto genera 120 llamados HTTP para los correspondientes 120 años de historia - Invocar el llamado HTTP para la URL generada en el punto 1
Obtener el resultado - Utilizar la librería Beautifulsoup para extraer las etiquetas HTML que contengan los datos relevantes para cada sismo/registro, almacenando el resultado en un dataframe
- Almacenar el resultado en un archivo CSV
El script completo para la extracción de estos datos se encuentra aquí
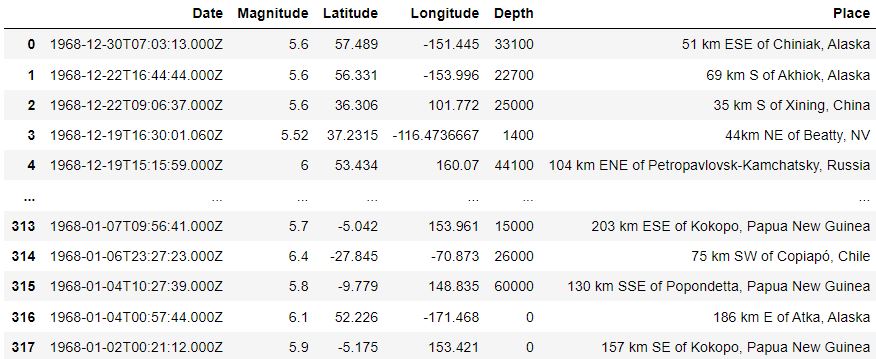
Preprocesamiento de datos
Si bien el XML resultante entrega la descripción del lugar donde ocurrió el sismo, es necesario separar este campo en ciudad y país.
Conocer la ciudad más cercana al epicentro del sismo permite contar con un atributo valioso a la hora de utilizar modelos de machine learning
En la imagen anterior vemos que el atributo Place está formado por
Distancia desde el epicentro hasta la ciudad más cercana
Separador coma
Ciudad
Separador coma
País
Bajo esta premisa, es posible construir una rutina adicional que permita agregar los campos City y Country a partir del atributo Place
El código implementado para esta fase se encuentra disponible aquí
El resultado es el siguiente
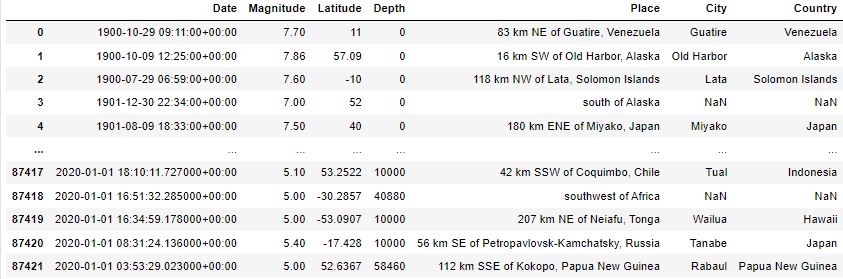
Análisis exploratorio de datos
Una vez añadidos los atributos City y Country, es posible pasar a la etapa de análisis exploratorio. Esto mediante el uso de algunas librerías matemáticas de Python que permiten obtener métricas y gráficos estándar para el mejor entendimiento de los datos.
Esto permite también poder decidir cuál es el mejor modelo predictivo que se ajuste a los datos.
Por ejemplo, la siguiente es una lista ordenada de la cantidad de sismos grado 7 (Richter) o mayor por país
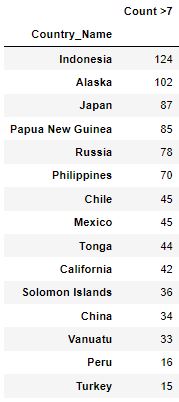
Para visualizar el análisis exploratorio completo, hacer click aquí
